

はじめに
書くこと
AWSのAuroraクラスター(以下、DBクラスターと記載)ですが、停止状態にしても1週間後に自動的に起動します。
そのまま気づかず起動状態にしていると、思わぬ料金が発生してしまいます。
停止状態にし続ける方法を考えてみました。
書くきっかけ
同じような内容が書かれた記事はあったのですが、自分の環境ではうまく動作しませんでした。
うまく動作しなかった理由は、DBクラスターに紐づくDBインスタンスに’利用可能’ステータスではないものが存在したためでした。
DBクラスターに紐づくすべてのDBインスタンスが’利用可能’ステータスのときDBクラスターを停止することができます。
そのため本記事では、Lambdaに実装するPythonスクリプトでDBクラスターに紐づくすべてのDBインスタンスが’利用可能’ステータスであることを確認した上でDBクラスターを停止するやり方を記載します。
全体の処理の流れ
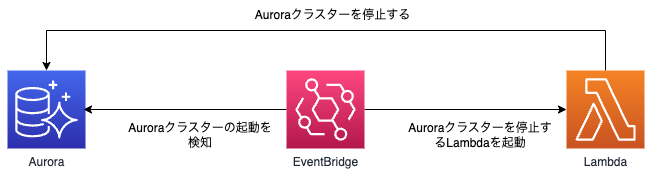
全体の処理の流れは以下のようになっています。
- DBクラスターが起動する。”DB cluster started”のRDSイベントが発生する。
- EventBridgeが”DB cluster started”のRDSイベントを検知する。
- Lambdaが起動してDBクラスターを停止する。
※Lambdaに実装するプログラムの処理の流れは後述します。
構成
構成図
構成図は以下のようになります。
動作確認した環境
自分が動作確認した環境は以下のとおりです。
| 項目 | バージョン等 |
|---|---|
| DBエンジンのタイプ | Aurora (MySQL Compatible) |
| DBエンジンのバージョン | Aurora (MySQL 5.7) 2.11.2 |
| Lambdaランタイム | Python 3.9 |
やってみる
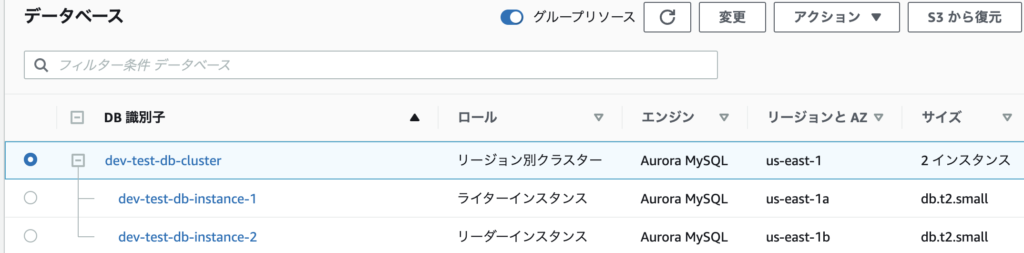
Aurora(DBクラスター)の状態
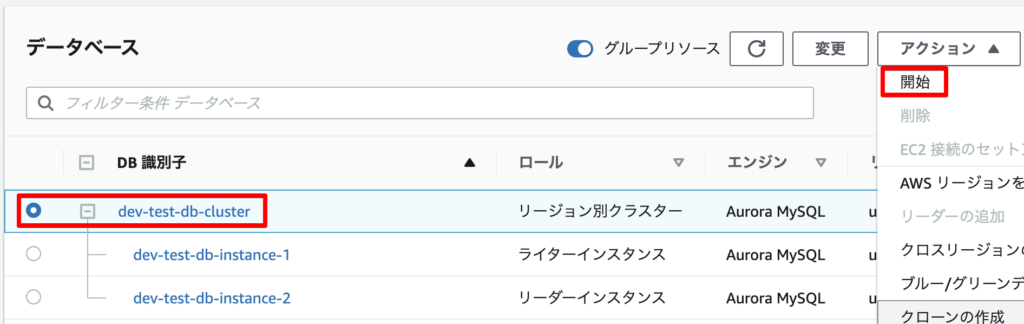
ここでは、DBクラスターの識別子がdev-test-db-clusterで、2つのDBインスタンス(dev-test-db-instance-1とdev-test-db-instance-2)を持っているDBクラスターを停止させることを考えます。
Lambda
Lambda関数を作成していきます。
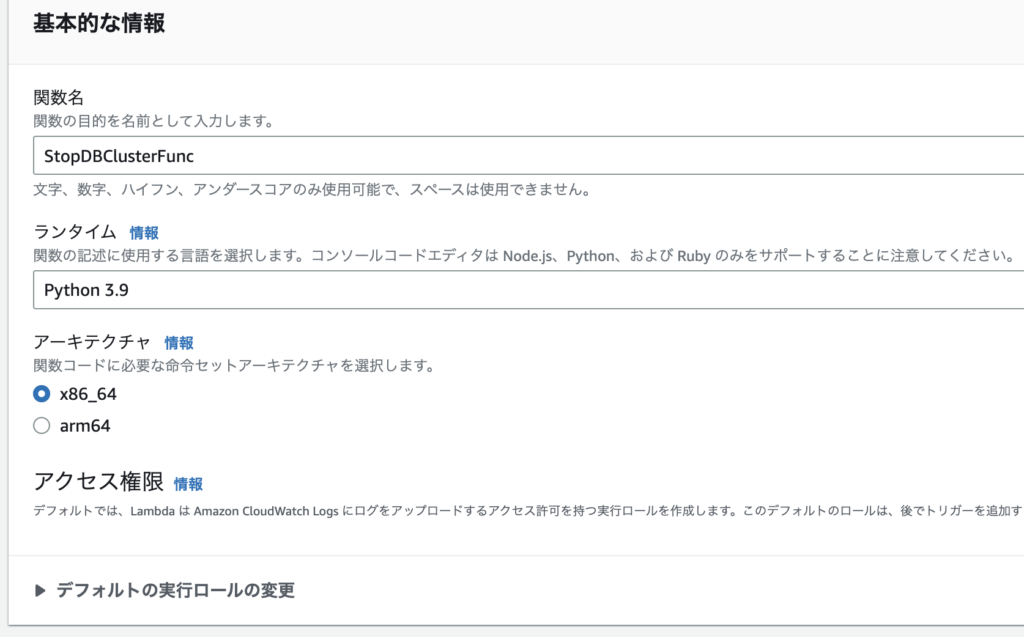
関数の作成
関数の名前はStopDBClusterFuncにしました。
ランタイムはPython 3.9です。
ほかはすべてデフォルトです。(Lambda関数に基本的な権限でロールが作成されます。)
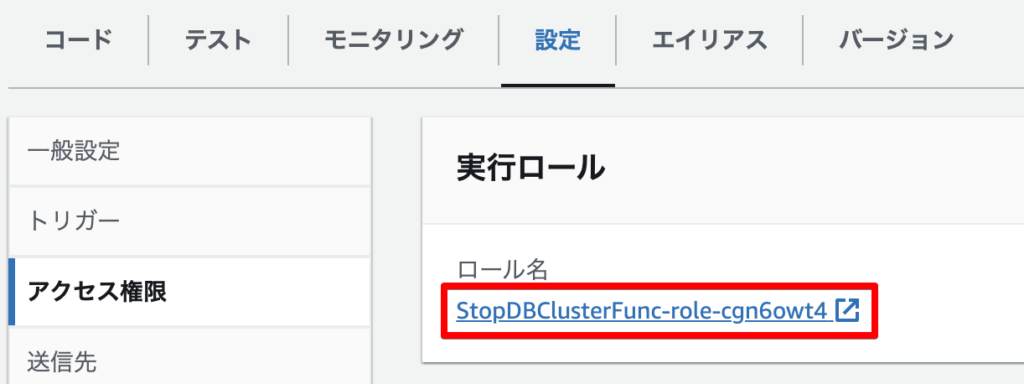
作成されたロールをクリックします。
「ポリシーをアタッチ」からポリシーを付与します。
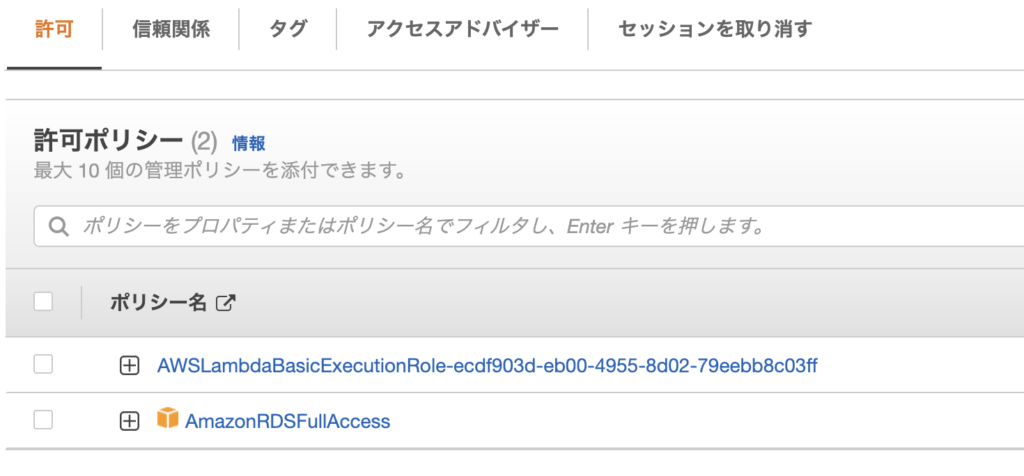
PythonからRDSのSDKを呼び出すので、ここではAmazonRDSFullAccessをアタッチしました。
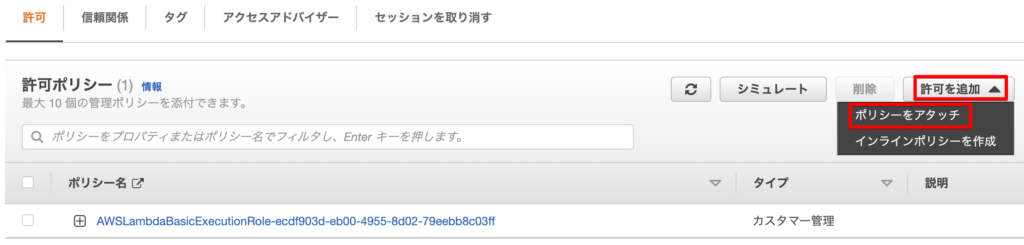
最終的には下記のような状態になります。
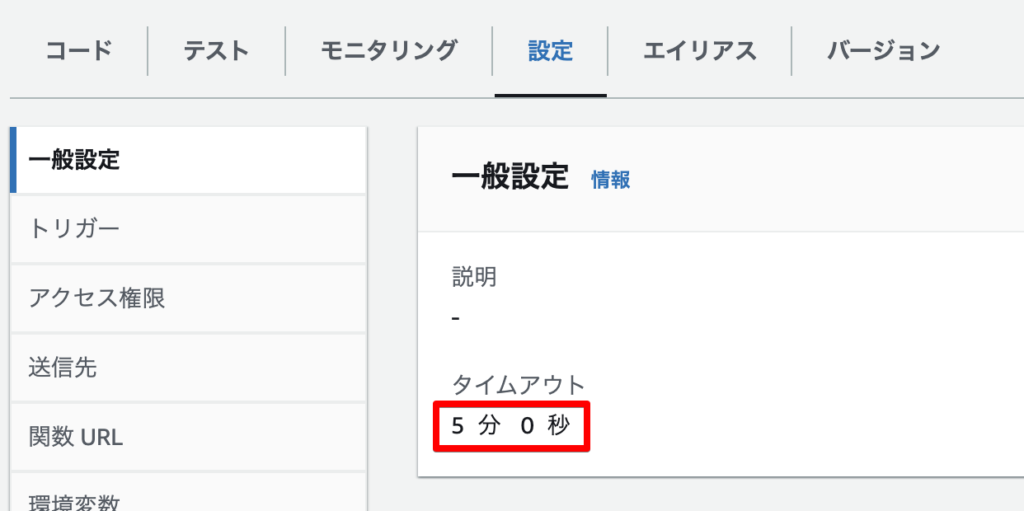
あと、タイムアウトも5分ほどに延長しました。
プログラムの作成
プログラムの処理の流れは以下のようになっています。
- EventBridgeから送られてきたRDSイベントのメッセージからDBクラスター識別子を取得する。
- DBクラスター識別子から、紐づくDBインスタンスの識別子を取得する。
- DBインスタンスの識別子に対して順番に、
boto3のwaiterを使用してステータスが’利用可能’であることをポーリングで確認する。(ポーリングの試行回数と再試行間隔はプログラムで指定可能) - ‘利用可能’ステータスであることが確認できたら、
available_instance_number変数に1をインクリメントする。 - 最後に、’利用可能’ステータスであるDBインスタンスの数と、DBクラスターに紐づくDBインスタンスの数が一致した場合にのみ、DBクラスターの停止処理を実行する。
プログラム
下記のコードをLambdaに組み込みます。
import boto3
import json
import time
rds = boto3.client('rds')
def lambda_handler(event, context):
# RDSイベントメッセージからDBクラスターの識別子を取得する
for key, value in event.items():
if key == 'detail':
cluster_identifier = value['SourceIdentifier']
# DBクラスター識別子からDBクラスターの情報を取得する
response_clusters = rds.describe_db_clusters(
DBClusterIdentifier=cluster_identifier
)
available_instance_number = 0
# DBクラスターの情報からすべてのDBインスタンスの識別子を取得する。
# すべてのDBインスタンスが'利用可能'('available')ステータスになるまでwaitする。
# ひとつでも'利用可能'ステータスにならなかった場合はDBクラスターの停止処理を行わない。
for db_cluster_members in response_clusters['DBClusters'][0]['DBClusterMembers']:
db_instance_identifier = db_cluster_members['DBInstanceIdentifier']
try:
waiter = rds.get_waiter('db_instance_available')
waiter.wait(
DBInstanceIdentifier=db_instance_identifier,
WaiterConfig={
'Delay': 5, #30,
'MaxAttempts': 5 #10
}
)
print("{}のステータスは'利用可能'です。".format(db_instance_identifier))
available_instance_number += 1
except Exception as ex:
print(ex)
print("{}のステータスは'利用可能'ではありません。".format(db_instance_identifier))
# DBクラスターに紐づくDBインスタンス数を取得する
instance_number = len(response_clusters['DBClusters'][0]['DBClusterMembers'])
# '利用可能'ステータスのDBインスタンスと、DBクラスターに紐づくDBインスタンス数が同じ場合は
# DBクラスターを停止する。
if available_instance_number == instance_number:
print('DBクラスターの停止処理を開始します。')
response_stop_clusters = rds.stop_db_cluster(
DBClusterIdentifier=cluster_identifier
)
print(response_stop_clusters)
else:
print("'利用可能'ステータスになっていないDBインスタンスがあるようです。DBクラスターの停止処理を行いません。")
EventBridge
EventBridgeでルールを作成します。
ルールの作成
名前はwatch-DBClusterStartedとしました。
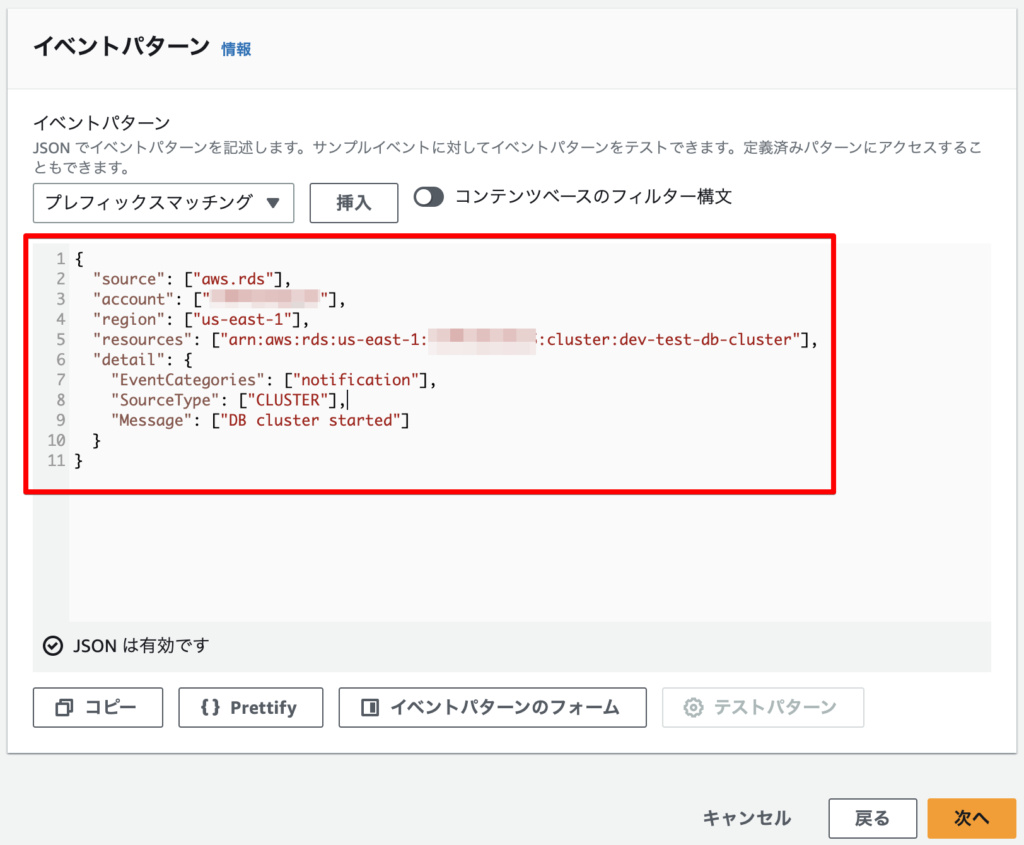
イベントパターンに、下記のJSONコードを記載します。(AWSアカウントIDはマスクしています。)
タイプがクラスターの、メッセージが”DB cluster started”である、RDSイベントを検知するイベントパターンです。
resourcesにDBクラスターの識別子を指定することにより、検知するDBクラスターを指定しています。
※ここで指定していないDBクラスターは検知されないので停止されません。
{
"source": ["aws.rds"],
"account": ["XXXXXXXXXXXX"],
"region": ["us-east-1"],
"resources": ["arn:aws:rds:us-east-1:XXXXXXXXXXXX:cluster:dev-test-db-cluster"],
"detail": {
"EventCategories": ["notification"],
"SourceType": ["CLUSTER"],
"Message": ["DB cluster started"]
}
}
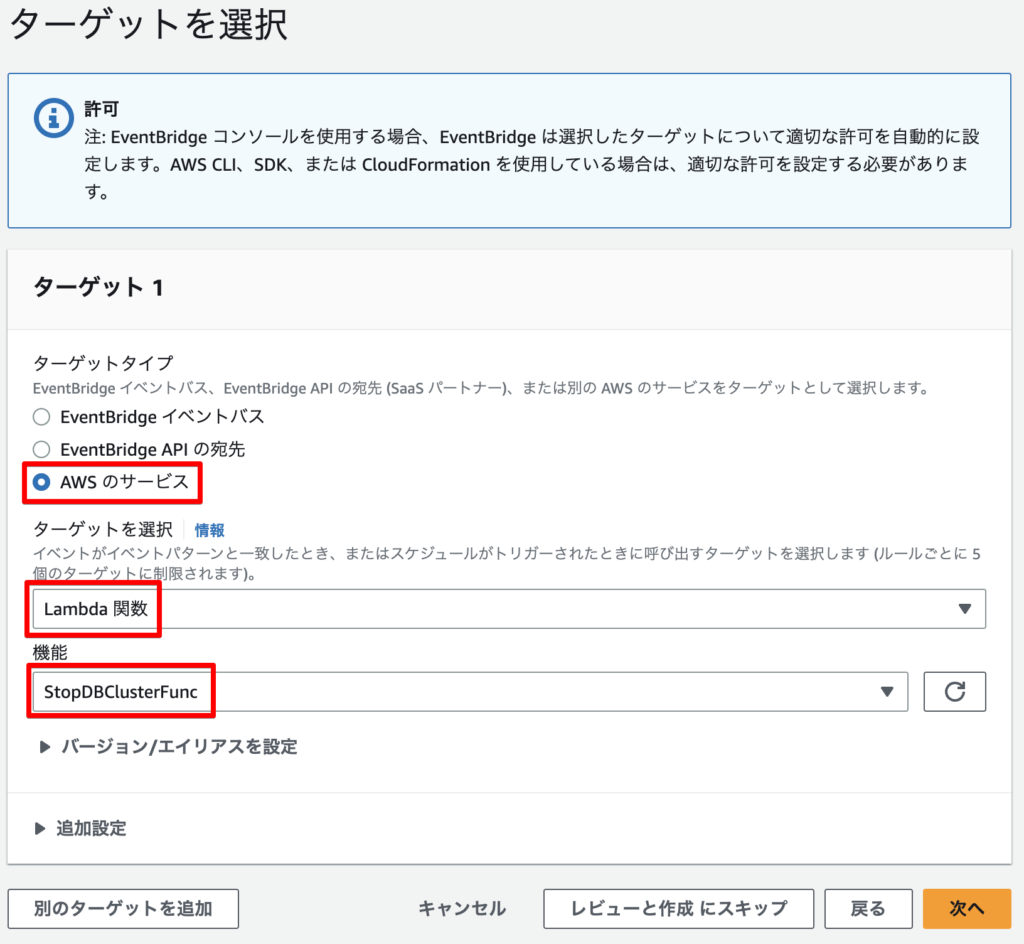
ターゲットは先ほど作成したLambda関数StopDBClusterFuncになります。
動作確認
DBクラスターを起動します。
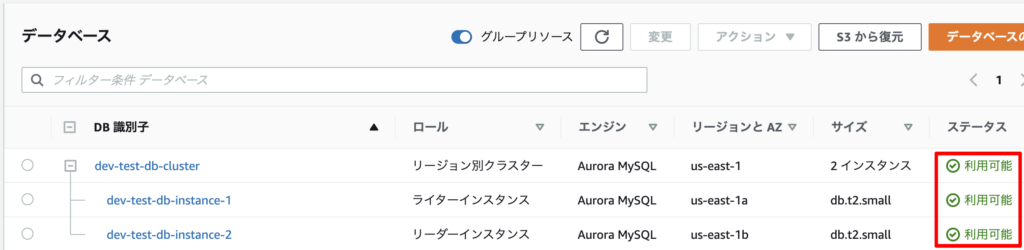
しばらくすると、DBクラスター識別子とDBインスタンス識別子で、ステータスが利用可能となります。
このちょっと前にもうLambda関数は動き始めています。
ログを見ると下のような感じになっています。
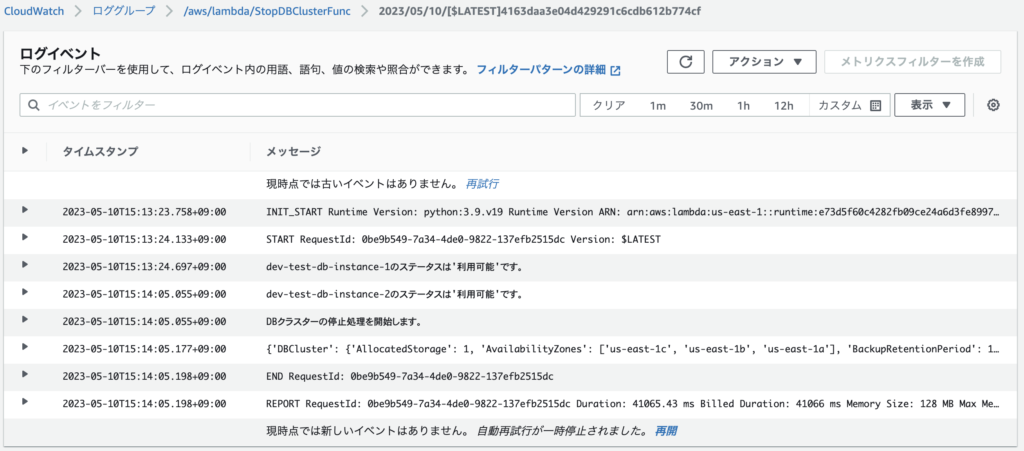
Lambdaが動き始めたとき、2つ存在するDBインスタンスは’利用可能’ステータスであったようです。
紐づくすべてのDBインスタンスが’利用可能’であることを確認した上で、DBクラスターの停止処理に入っています。
RDSコンソールの画面を更新すると、DBクラスターは停止中となっていました。
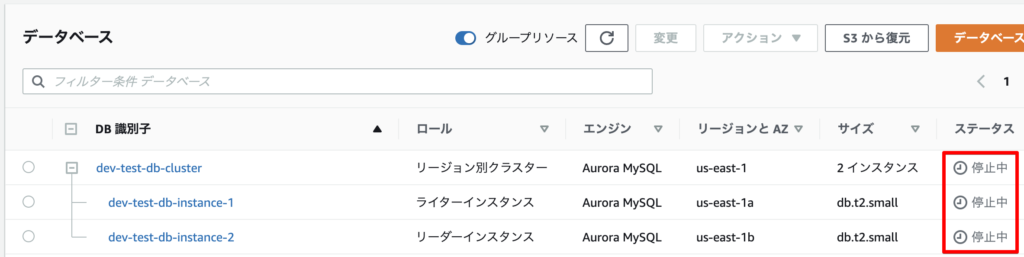
これで、作成したEventBridgeのルールを有効にしている限り、このDBクラスターは起動したら停止されますので、起動状態にはならなくなります。
テスト環境には使えそうですね。








コメント